



遺伝子情報の大容量化を支える計算機ネットワーク


大学共同利用機関法人 情報・システム研究機構 国立遺伝学研究所では、国際的な塩基配列データベースである「DDBJ」(DNA Data BANK of Japan:日本DNAデータバンク)の構築・運用とスパコンによる計算機サービスを提供しています。
その活動内容とSINETの役割について、国立遺伝学研究所 大量遺伝情報研究室教授 中村 保一氏と、同 遺伝子発現解析研究室助教 小笠原 理氏にお話を伺いました。
(インタビュー実施:2013年11月14日)
まず、遺伝学研究所の概要について教えて頂けますか。
中村氏:1949年に設立された遺伝学研究所は、日本の生命科学分野における中核研究機関として様々な研究を行っています。 また、大学共同利用機関として全国の研究者に共同研究の機会や施設を提供すると同時に、総合大学院大学 生命科学研究化の遺伝学専攻も担当しています。 遺伝学に関わる先端研究や教育を、総合的に行う機関と思って頂ければ良いのではないでしょうか。
具体的な事業内容としては、まず「バイオリソース(生物遺伝資源)事業」が挙げられます。 ここではマウスやショウジョウバエといった学術研究用生物の開発・収集・提供を行うと共に、生物遺伝資源データベースの構築と公開運用も進めています。
2つめは「先端ゲノミクス推進事業」で、最先端の次世代シーケンサーを導入してゲノム情報の解析などを行っています。 そしてもう一つが、私も携わっているDNA塩基配列情報の国際的なデータベース「DDBJ」です。


小笠原氏:塩基配列の決定方法であるサンガー法が開発されたことなどをきっかけに、今後は大量の塩基配列データが生成されていくであろうことが決定的となりました。 欧米ではこうした動きに対応すべく国際的なデータベースを作ろうという機運が高まったのですが、日本にもこの取り組みに参加して欲しいという要請があったのですね。
現在DDBJでは、米国のNCBI(National Center for Biotechnology Information:国立生物工学情報センター)が提供する「GenBank」、欧州のEMBL-EBI(European Bioinformatics Institute:欧州バイオインフォマティクス研究所)が提供する「ENA」と共同で「INSD(International Nucleotide Sequence Database:国際塩基配列データベース)」を構築・運用しています。
DDBJの活動目的や意義についても伺いたいのですが。
中村氏:遺伝子の塩基配列情報は、生物学や医学、農学など幅広い分野の研究と関連しています。 そして研究を行っていく上では、様々な現象がどの塩基配列と関連しているのかを解き明かすことが重要なポイントとなります。 たとえば生物の進化で言えば、様々な生物の塩基配列を比較して違いを調べ、並び方が似ていれば進化の系統上で近い位置にある、大きく違っていれば遠い位置にあるといったことが分かってくるわけですね。 とはいえ、その塩基配列データがどこかにきちんとアーカイブされていないと、情報の再利用も繰り返し実験もできません。
その点、DDBJに蓄積された塩基配列データには、統一的なIDが割り当てられており、採取された場所や生物の部位といった付随データも整理されています。 これを利用することで、研究を正確に効率よく進められるというわけです。 ちなみに、遺伝子に関連した学術論文を書く場合には、DDBJ、GenBank、EMBLのいずれかのIDを明記することが求められます。
この分野では研究データの大容量化が加速度的に進んでいるとのことですが。
中村氏:その大きな要因となっているのが、塩基配列の決定に利用するシーケンサーの飛躍的な性能向上です。 特に次世代シーケンサーと呼ばれる最新の装置では、以前の装置より4~5桁も性能が上がっています。 これに伴って、アーカイブに登録されるデータの容量も増える一方です。 しかも、INSDでは、DDBJ、GenBank、EMBLの三極で全て同じデータを持つようにしていますから、各機関同士でコピーするデータも相当な容量に上ります。 なお、遺伝研ではスパコンを利用した計算機サービスも提供していますが、こちらに求められる能力もどんどん高くなっていますね。
研究を支えるICTインフラにも相当な負荷が掛かりそうですね。現在はどのような環境を構築されているのですか。
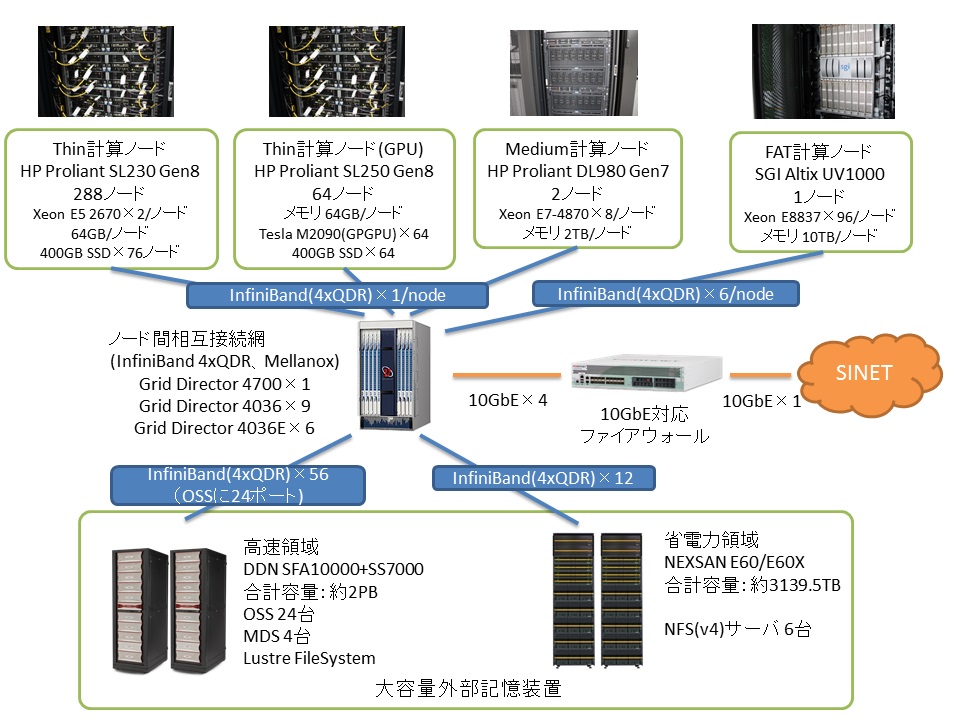
小笠原氏:まずスパコンについては、次世代シーケンサーへの対応を図るために、今回の調達からアーキテクチャを見直して業務ソフトウェアも全面的に書き換えました。 その結果演算性能も大幅に強化され、旧スパコンの理論ピーク演算性能20TFLOPSに対して現在は169TFLOPSを達成。中間増強後は366TFLOPSにまで向上する予定です。
ストレージについても同様で、ディスク0.65PB/テープ0.75PBだった旧スパコンに対し、現在は計算用2PB/アーカイブ用3PBの容量を確保。中間増強後はそれぞれ7PB、5.5PBに拡張される予定です。
システム面での特徴としては、とにかくI/O負荷が重いという点が挙げられますね。 多い時には一日50万件ものデータが登録されますし、データベースのインデックスを作るのも結構厳しい。そこで並列分散ファイルシステムのLustreを使うなど、I/O処理の高速化にはかなり気を遣っています。 ちなみに計算機ノードとしては、10TBのメモリを搭載したFat nodeが1ノード、2TBのメモリを搭載したMedium nodeが2ノード、その他に64GBのメモリを搭載したThin nodeが352ノード稼動しています。
ネットワークについてはどうでしょう。
小笠原氏:DDBJには約1100名近い研究者の方々がユーザーとして登録されており、毎日のように塩基配列データのアップロードやスパコンを利用した解析作業を行われています。 また、その他にGenBankやEMBLとのデータ交換も行いますので、研究所内のトラフィックよりも外部とのトラフィックの方が格段に多い状況です。 DDBJの情報やスパコンの計算機資源は日本のDNA研究を支える重要な基盤ですから、ネットワークにも高い性能と信頼性が要求されます。
その点、SINETがこの部分をしっかりと支えてくれていますので、研究者の方々にも安定的なサービスを提供できています。現在は常時3~4Gbpsの帯域を利用していますが、ネットワークに関する不満は感じないですね。



最後に今後の展開について伺えますか
中村氏:DDBJとしては、今後も大量の塩基配列データの確実なアーカイブや、計算機資源の提供が重要なミッションとなります。 とはいえ、何度も触れている通り、データの大容量化やシーケンサー/計算機の高性能化はとどまる気配を見せません。 ネットワークの帯域もあればあるだけ使いたいような状況ですので、SINETの今後の発展にも大いに期待しています。